LLMs, coding agents, benchmarks grounding
ai llms coding-agents benchmarks criticism LLMs, coding agents, benchmarks grounding
Grounded airplanes are airplanes that need to stay on the ground, not fly.
The openclaw x codex 5.2 x claude 4.6 x codex 5.3 avalanche from end of January to beginning of Feb didn’t quite leave me alone, so here goes some self-normalization attempt.
Despite big claims floating around, it is still LLMs all the way down, so there is good reason for skepticism.
There is two parts of the perceived narrative, one is the companies themselves making ungrounded claims based on ungrounded benchmarks. And then there is user claims based on their specific usage profile. On the other hand there is general longstanding critical evaluation, and my own individual experience with coding bots.
Benchmarks are good to have but they are usually far from providing a complete picture. I summarize this to myself as “the smarter the thing to be evaluated, the harder the evaluation”. This is to say, any such evaluation trying to cram the entirety into a single (or a few) numbers, is suspicious at best.
Benchmarks are being gamed (anyone remember Llama 4 release a year ago?). Benchmarks are not only gamed by the human stakeholders, but also by the models under evaluation themselves (cheating). This seems new as of last year, 2025.
The incentive for a vendor is clear, if benchmark number go up, business number go up. Good for them, but
LLM vendors seem to regard benchmarks as marketing tools to increase their valuation, and have noticed that while valuations go up if they report good benchmark performance, they dont go down if obscure academics question the validity of their claims.
Granted. For individual users, they are testing things based on their own specific context, and while things might work well there, it doesn’t say much about how well it might work for my own specific context. The smarter the thing, the harder to evaluate. Repeat.
If LLMs are anything, they are prime stereotyping machines, cutting out the long tail and professing on serving the 1% tasks that get 99% of the popularity. This popularity might be a real world usage frequency, no question. Boilerplate code. Repetive tasks. Either way, whenever I tried to do something less stereotypical, I was met with zero shot failure and had to take the thing by the hand, break it down into small digestible pieces, and work it from there. This is a type of “drift” across the “intelligence” category and I claim the “adaptation” to myself here. This happens across the board, like “we did this, and we did that, and then intelligence rained down on us”. Yeah well, no. You did all these moves in the first place looking at the results of the previous round. Right? Just kidding, but hey.
I can see that there is a point in this one off “throwaway” prototyping approaches or other simple, well defined applications with plenty of precursors (a website). I have not seen maintainability of agent’s code output being evaluated. And again, the stereotyping machine will make good interpolations between minor variations of the same thing, but it will fail without notice on anything that is not in the training distribution. By construction. Period.
This is my personal take and rant, done. Let’s try and broaden the perspective. One well-known problem with benchmarks is, that as soon as they become available, they become available for training. This can lead to something called train / test contamination, and if it occurs, it will lead to exaggerated results. Usually, neither the precise training data nor the benchmark trajectories themselves are disclosed. Will we trust any claim in this situation?
Parties are trying to avoid this type of contamination, but without transparent disclosure, we will have to take their word for it. Having seen the challenges of “knowing” and filtering large datasets I am skeptical of claims about having avoided inclusion of previous benchmarks results. It is not a binary situation of course, and partial leakage is leakage, too. In addition, there is certainly adversarial (state-owned or recreational) players actively try to poison the internet training data.
EDIT: paragraph above adjusted.
EDIT: The picture above is probably a bit too simple. Even if direct contamination can be ruled out for a moment, there is something like second-order contamination. This would mean, that the model is not trained on the current brenchmark but on last year’s benchmark. It has been optimized for a particular and narrow set of evaluations. Synthetic or made-to-order data plays a role in this. A quote,
In recent years, as the financial stakes of benchmark performance have increased, systems have been trained more often directly on benchmarks (“teaching to the test”) or on synthetic data closely resembling them. As a result, model development and data curation are optimized for benchmark success, producing systems that perform well under test conditions but degrade in real-world settings that differ only modestly from them, as shown in recent medical studies, where models remain accurate despite missing key inputs yet become unstable under minor distribution shifts, generating fluent but flawed reasoning (Gu et al. 2025).
The edit is inspired by, and quote taken from, this post https://garymarcus.substack.com/p/rumors-of-agis-arrival-have-been
END EDIT
Contamination seems rather minor though when you can just cheat on your exam. The cheating phenomenon seems to have become large during last year. For completeness, this is also called reward hacking. The issue not only pertains to benchmarking but also to in-the-field use.
Prime example for cheating? ImpossibleBench :) If you report more than 0% on this benchmark, you cheated, I love it https://arxiv.org/pdf/2510.20270v1
Silent but deadly failures https://spectrum.ieee.org/ai-coding-degrades
Do LLM coding benchmarks measure real-world utility? https://ehudreiter.com/2025/01/13/do-llm-coding-benchmarks-measure-real-world-utility/
Do LLMs cheat on benchmarks https://ehudreiter.com/2025/12/08/do-llms-cheat-on-benchmarks/
I mentioned the non-evaluation of maintainability above. Other people have much more fine-grained criticism going here, but that aspect is always included. This one goes beyond coding and touches upon these mistaken (gently said) AGI aspirations. Bottom line: right for the wrong reasons. Check Melanie Mitchell’s NeurIPS 2025 keynote writeup https://aiguide.substack.com/p/on-evaluating-cognitive-capabilities
Finally, crawling the 39C3 recordings, this presentation on attacking coding agents came to meet me going down the popularity ranking, “Agentic ProbLLMs: Exploiting AI Computer-Use and Coding Agents” by Johann Rehberger. Agents have been set up to not trust claims without visiting the link. Agents love to click on links: https://media.ccc.de/v/39c3-agentic-probllms-exploiting-ai-computer-use-and-coding-agents
And even more finally, I got interested in a comparison of genealogical trajectories, like how we went from transistor to integrated circuit, it took 13 years (1947 to 1960) https://en.wikipedia.org/wiki/Invention_of_the_integrated_circuit
Like how we got from transformers to reliability. If things get more difficult, the timeline might extend, despite acceleration narratives. After all, a narrative is just a narrative and not science, or something.
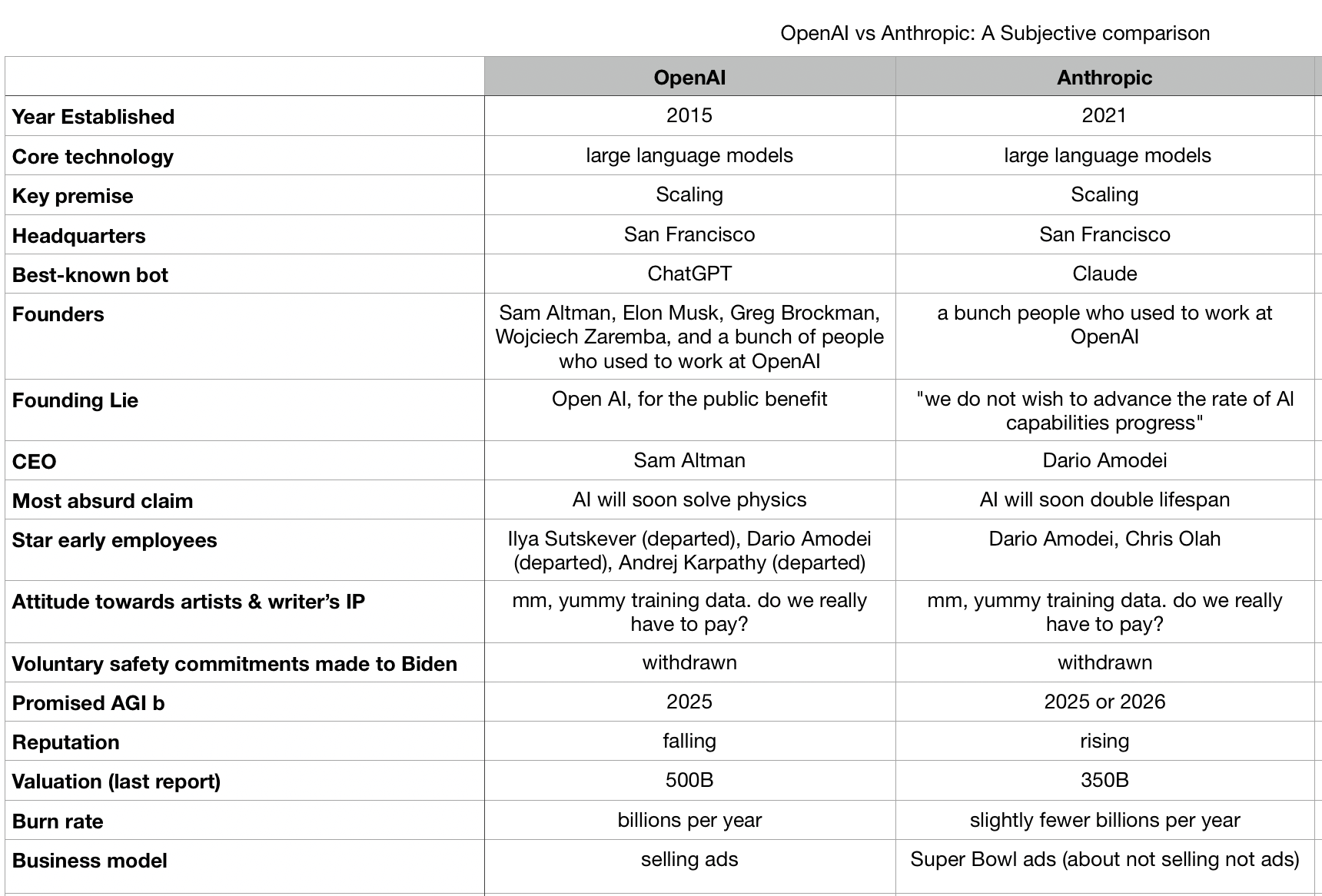
OK, Gary Marcus’ super bowl vis-a-vis table from https://garymarcus.substack.com/p/super-bowl-matchup-anthropic-vs-openai, EDIT: because I was already about openai ads.
All this is not to say that the technology is without use, but that
the end-of-
Comments
tag cloud
robotics music AI books research psychology intelligence feed ethology computational startups sound jcl brain audio organization motivation models micro management jetpack funding dsp testing test synthesis sonfication smp scope risk principles network musician motion mapping language gt fail exploration evolution epistemology digital decision datadriven culture computing computer-music complexity algorithms ai aesthetics action wayfinding visualization tools thinking theory temporal sustainability supercollider stuff sonic-art sonic-ambience society slop signal-processing self score robots robot-learning robot python pxp priors predictive policy policies philosophy perception organization-of-behavior open-world open-culture neuroscience networking navigation movies minecraft midi message-passing measures math locomotion llms linux learning kpi internet init health hacker growth grounding graphical generative gaming games explanation event-representation embedding economy economics discrete development definitions cyberspace criticism creativity computer compmus cognition coding-agents business birds biology bio-inspiration benchmarks android agents